 SeedBase
SeedBase
Prisma test data, FK-consistent, straight from your schema.prisma
Maintaining a prisma/seed.ts by hand means writing insert logic per model, and it rots the moment the schema moves. Copying a production dump into your dev database is a GDPR problem waiting to happen. The fix: generate Prisma test data straight from your schema, foreign-key-consistent and realistic, then drop it into the workflow you already run. Seed the repo with seedPrisma() and prisma db seed, pull in-memory fixtures with seededRows(), or write a SQL file for CI. Data that actually looks real, not "Premium Widget 1" and lorem ipsum.
Free tier, no card. Want to see the output before wiring anything up? Try the login-free sandbox: paste a schema, generate, look at the rows.
Related: in-depth Prisma seed data · Snaplet Seed alternative · SQL test data
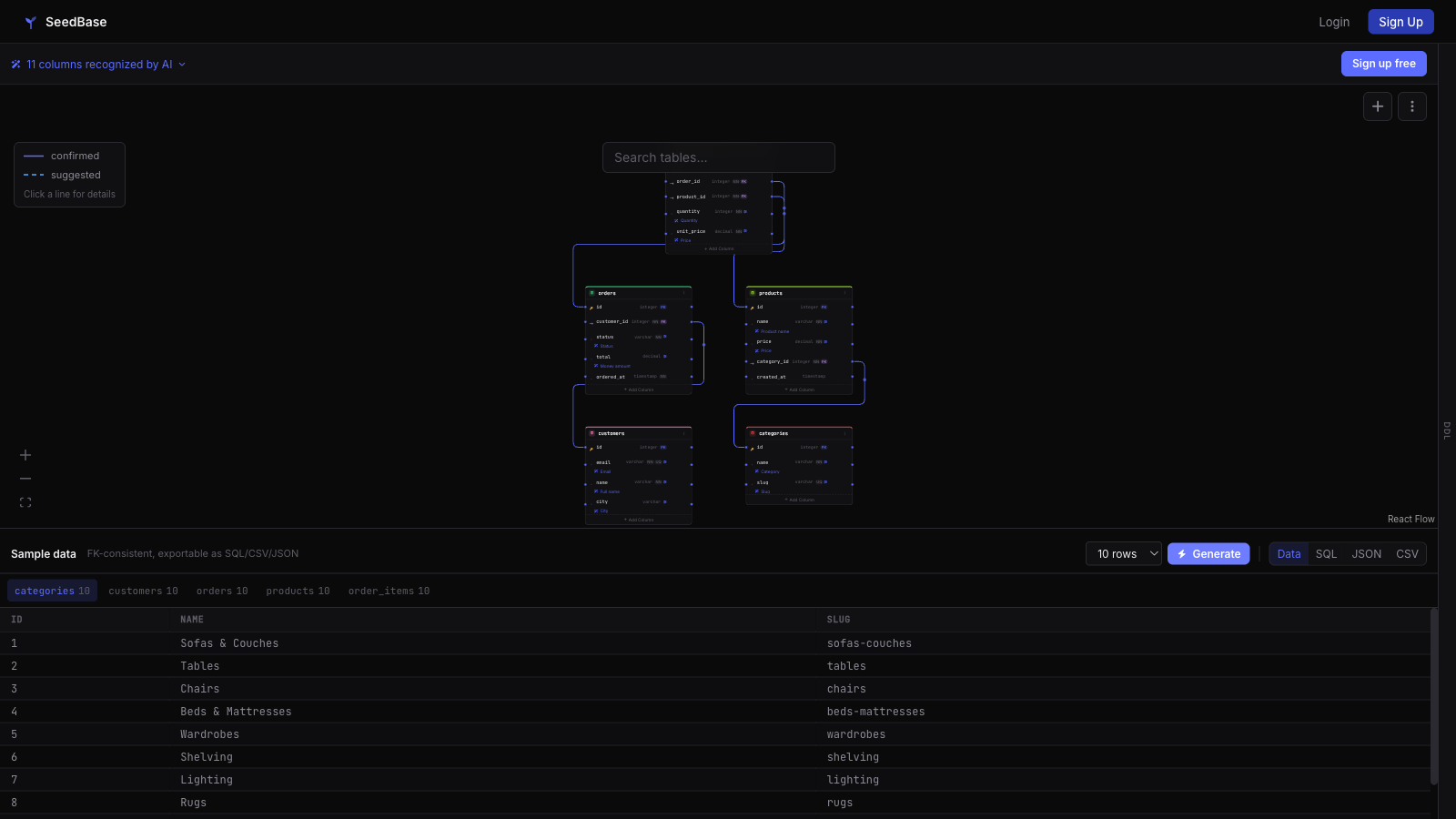
Seed your Prisma database in one call
Pull SeedBase in as a dev dependency and call seedPrisma from your seed file. It generates and loads foreign-key-consistent data through the same PrismaClient your app uses, so your schema has to exist first, which prisma migrate already owns.
// prisma/seed.ts
import { PrismaClient } from "@prisma/client";
import { SeedbaseClient } from "@seedbase/client";
import { seedPrisma } from "@seedbase/client/prisma";
const prisma = new PrismaClient();
const client = new SeedbaseClient({ token: process.env.SEEDBASE_TOKEN });
await seedPrisma(prisma, client, { project: process.env.SEEDBASE_PROJECT, seed: 42 });With that file in place, run prisma db seed and Prisma executes it. Install SeedBase as a dev dependency first:
npm install --save-dev @seedbase/clientThe seedPrisma helper does the work: it generates a realistic, FK-consistent dataset for your schema and writes it through the same Prisma connection your app uses. No insert logic per model, no manual wiring between parents and children. Your schema must exist already, which prisma migrate owns, and SeedBase fills it FK-safe.
Realistic data, not "Premium Widget 1"
The point is not just filling rows, it is filling them with data a real query would actually return. SeedBase resolves foreign keys across tables, uses realistic distributions, and writes coherent free text instead of repeating a placeholder, so a customerId on an order points at a customer that exists and a product name reads like a product, not "Premium Widget 1".
- Foreign keys resolve across tables: every child row points at a parent that exists, so the data loads with constraints on.
- Realistic distributions and coherent free text, not placeholders, so your queries and assertions hit data that looks real.
- One call replaces the pile of per-model insert logic and the wiring between them.
In-memory Prisma test data fixtures with seededRows()
Sometimes you want the rows for a test fixture or factory, not an insert. client.seededRows(project, { seed, rows }) generates the dataset and hands it back as a plain object keyed by table name, already in foreign-key-safe order, so a parent row exists before any child that references it. No database round-trip in the test, no manual ordering.
import { SeedbaseClient } from "@seedbase/client";
const client = new SeedbaseClient({ token: process.env.SEEDBASE_TOKEN });
const rows = await client.seededRows(process.env.SEEDBASE_PROJECT, { seed: 42, rows: 100 });
// rows.User, rows.Order, rows.OrderItem ... in FK-safe order
const firstOrder = rows.Order[0];
const owner = rows.User.find((u) => u.id === firstOrder.userId); // always resolvesBecause the same seed always returns the same rows, your fixtures are stable across machines and CI runs. Use them to back a factory, prime an in-memory store, or assert against data that looks like something a real query would return.
A Prisma seed SQL file for CI with generate() and download()
For a pipeline that loads SQL before the test suite runs, generate once and download the artifact. client.generate(project, { seed, wait: true }) runs a generation and waits for it to finish, then client.download(gen.id, { format: 'sql' }) returns the bytes you write to disk.
import { writeFile } from "node:fs/promises";
import { SeedbaseClient } from "@seedbase/client";
const client = new SeedbaseClient({ token: process.env.SEEDBASE_TOKEN });
const gen = await client.generate(process.env.SEEDBASE_PROJECT, { seed: 42, wait: true });
const sql = await client.download(gen.id, { format: "sql" });
await writeFile("seed.sql", sql);Load seed.sql with psql (or your database client) before the tests, and because the data is keyed off the seed, a failing CI run reproduces locally with the same seed: 42. For the deeper version of all three paths, with @relation fields and @unique one-to-ones, see the in-depth Prisma seed data guide.
A real alternative to hand-written seed scripts
A handful of prisma.user.create calls is fine. A real schema is not. Once you have dozens of models, your seed script has to know which parent rows exist, which relations to satisfy, and which derived totals to keep in sync. You end up maintaining a second, worse copy of your schema in your seed file.
- Seed scripts drift: add a required field and the inserts that miss it start failing.
- Insert logic multiplies: one block per model, plus all the ordering so children come after their parents.
- Production dumps are a GDPR problem: real names, real emails, real card data sitting in your dev database.
- The data looks fake, so tests pass against rows no real query would ever return.
SeedBase replaces all of that with one call that reads your schema, resolves the foreign keys for you, and seeds realistic data in the right order. If you came off @snaplet/seed and createSeedClient(), this is the maintained equivalent: the Snaplet Seed alternative page walks through the move, and your schema.prisma does not change.
Deterministic and reproducible
Generation is seeded. The same seed produces the same data, every run. That keeps CI reproducible: the same prisma db seed run yields the same rows on every machine, so a green build stays green for the right reason. When a test fails, reuse the seed and you reproduce the exact dataset that broke it, instead of chasing a seed script that has since been hand-edited.
Free tier: generate, download, seed
Generation and JSON download are free to use. You do not need push-to-database or any paid feature to seed your Prisma database, because the data loads through your own PrismaClient. Generate once, run prisma db seed, and let it fill the schema prisma migrate already owns.
Try it
There is a runnable example, so you can clone it, run the seed, and watch a real FK-consistent dataset get written to a database. Then point it at your own schema.
node packages/seedbase-node/examples/prisma-seed-demo.mjs- Paste a schema and look at the rows in the login-free sandbox, no account needed.
- Drive generation from your editor with the VS Code extension.
- Read the docs for the Prisma helper and the database connections.
- Create a free account at /register to generate against your own schema.
Stop hand-writing seed scripts.
Generate a foreign-key-consistent dataset once and seed your Prisma database with one call. Free tier, no card.
Create a free accountMore: in-depth Prisma seed data · Snaplet Seed alternative · Django test data · login-free sandbox · Test data fixtures · Docs · home
Frequently asked questions
How do I get Prisma test data into my repo workflow?
Add a prisma/seed.ts that calls seedPrisma(prisma, client, { project, seed: 42 }) from @seedbase/client/prisma, then run prisma db seed. SeedBase generates FK-consistent rows from your schema and inserts them through the same PrismaClient your app uses, in dependency order, so it lives in the repo next to your migrations.
Can I get Prisma test data as in-memory fixtures instead of inserting it?
Yes. client.seededRows(project, { seed, rows }) returns the data as a plain object keyed by table name, already in foreign-key-safe order, so a parent row exists before any child that references it. You build factories or fixtures off it without touching a database.
How do I produce a SQL seed file for CI?
Call client.generate(project, { seed: 42, wait: true }) to run a generation, then client.download(gen.id, { format: 'sql' }) to get the bytes. Write them to seed.sql and load it before your test suite. Same seed, same file, so a failing test reproduces locally with seed: 42.
How is this different from a hand-written prisma/seed.ts?
You do not write insert logic per model by hand. SeedBase fills the database foreign-key-consistent out of your schema with realistic data, so a row that points at a parent always finds a parent that exists, and the values look real instead of Premium Widget 1 or lorem ipsum.
Does it read my Prisma schema?
Yes. SeedBase reads schema.prisma or a live database, so it knows your models, fields and relations and fills them foreign-key-consistent without you describing the schema a second time.
Is it deterministic?
Yes, per seed. Generation is seeded, so the same seed produces the same data every run. That keeps CI reproducible: the same seed run yields the same rows, and a failing test can be reproduced exactly by reusing the seed.
Is it free, and what does the paid plan cost?
There is a free tier with no credit card, including schema import and generation, which is enough to seed a Prisma database through your own PrismaClient. Paid plans start at €19/month and add Parquet export, direct database push and higher row limits.